Do you know that Multicollinearity has almost no effect on the final accuracy of the machine learning model? So why is multicollinearity a problem, and what is it in the first place?
In this article, we will learn answers to such questions.
# Description
- The assumption in the Regression-based model.
- What is Collinearity?
- About Multicollinearity
- Why is Multicollinearity a problem?
- How to remove Multicollinearity?
- Using VIF and its Code Implementation
- Using Correlation and its Code Implementation
- A python library that automates the above methods.
# Assumption
It is very important to know that one of the assumption's for the regression-based model is —
- No or little multicollinearity i.e., Input features have no Correlation among themselves or in other words they are independent of each other.
But generally, it is not the case i.e the dataset contains features that are significantly correlated with each other. This leads to Multicollinearity.
Let's quickly see what is Coliniarity in brief.
# What is Collinearity?
Collinearity or Correlation is a statistical measure that indicates the extent to which two or more variables move together. In other words, it simply is a number(+ve or -ve) to indicate how are two features interacting with each other like if one increases the other feature is increasing, decreasing, or showing a random growth.
The correlation could be positive or negative. A positive correlation indicates that the variables increase or decrease together. A negative correlation indicates that if one variable increases, the other decreases, and vice versa.
# About Multicollinearity
As we all know that it is very important to understand what factors affect the growth of a business firm, this is done in many ways and one of them is by understanding the equation given by our machine learning model. Let's take an example -
No of Covied19 = 4*Area + intercept (Just an Assumption)
Let's say our model gave us the above equation which basically states that if the intercept is 0 then we can directly say that if the Area doubles the no of covid cases will increase by a factor of 4. As you can understand that knowing this factor as accurately as possible is very important because based on that we are supposed to decide the no of vaccines and hospital beds to produce daily.
# Why is Multicollinearity a problem?
So what does multicollinearity have to do with the above example?
Due to multicollinearity of we may get different coefficients for the same factors and hence leading to wrong interpretations, which could have serious effects. For example, we may get a factor as 2*Area but this will lead to a shortage of no of beds and vaccines which are produced daily and hence will lead to increase in no. of deaths per day.
In general, we can say that —
- Multicollinearity has a great negative impact on these coefficients and could lead to a wrong inference.
- Technically it also affects the p-values which again affects the feature selection process.
# How to Remove Multicollinearity?
In general, there are two different methods to remove Multicollinearity —
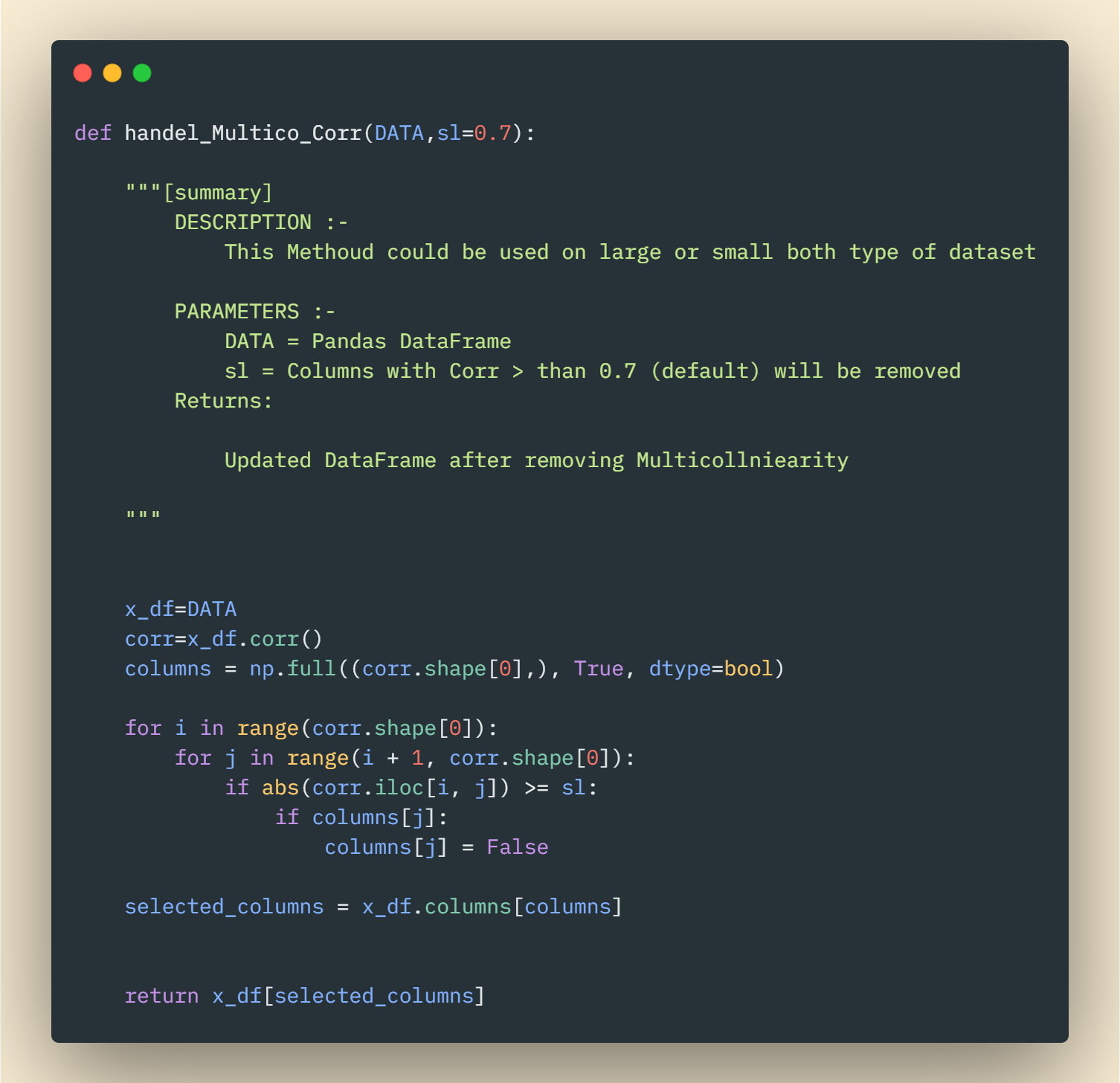
- Using Correlation
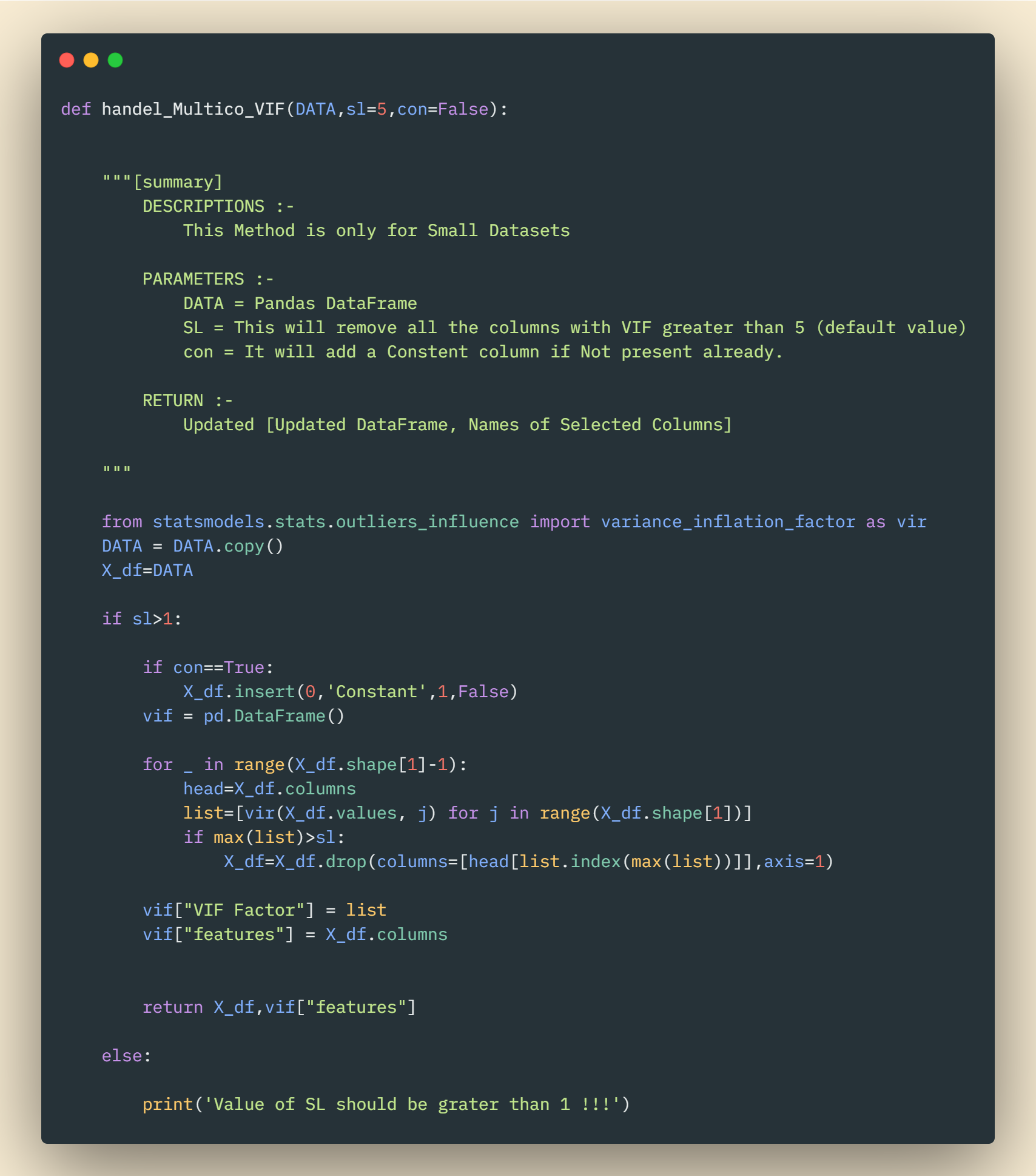
- Variation Inflation Factor (VIF) —
General, A correlation between two features is more than 0.7, which indicates the those features
A correlation greater than 0.7 between two features indicates the presence of Multicoliniarity and we should drop one of the two features to solve it.
Code
There is a simple test to identify multicollinearity called VIF (variance inflation factor). VIF starts with 1 and has no upper boundary. VIF between 1 to 5 is considered moderate, but if VIF is above 5 then those are to be removed.
R2 is the coefficient of Determination which indicates the extent to which a predictor can explain the change in the response variable.
A VIF of 10 means that the variance of the coefficient of the predictor is 10 times more than what it should be if there's no collinearity.
Code
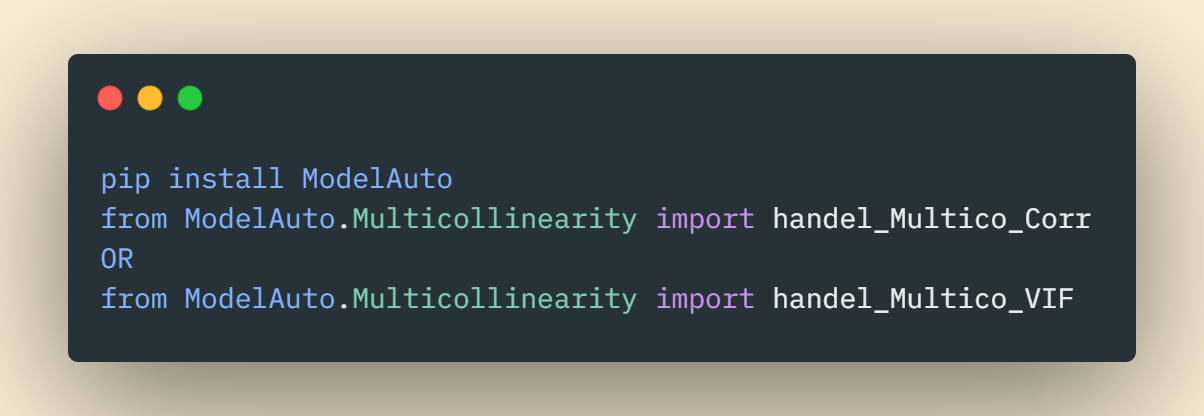
Library Support —
You can use the Python library ModelAuto to solve Muticoliniarity easily.
It has an inbuilt package to remove Multicoliniarity via both methods.
# Conclusion
Multicollinearity affects the coefficients and p-values, but it does not influence the predictions, precision of the predictions, and the goodness of fit. So if our primary goal is just to make predictions we don't need to reduce multicollinearity.
Majorly multicollinearity affects Linear models like-Linear Regression, Logistics Regression. Not much impact on the Algorithms like KNN, Decision Tree, etc which are non-linear.
Author

Sudhanshu Pandey
AI/ML Expert